
There’s a misunderstanding hiding beneath a lot of the excitement around large language models (LLMs) and AI. It’s not the obvious stuff about hype or overblown promises, though those are rampant right now with a study suggesting 95% of AI projects have zero returns. It’s much much quieter than that. It’s the assumption that these systems know things in the way humans know things. It’s the idea of Artificial general intelligence (AGI) – that these systems are somehow accumulating understanding over time, staying current as the world changes, and forming an internal model of reality as they go. The fact is, they aren’t, and the gap between that assumption and how these systems actually work explains a huge misunderstanding with a lot of people.
A language model is trained on a massive snapshot of data that ends at a very specific moment in time. Go look at any company’s LLM model page to find these dates. That snapshot is baked into the model and then frozen. From that point forward, nothing inside the model updates unless it is retrained. No matter how fluent, confident, or authoritative an answer sounds, the model has no native awareness of anything that happened after its cutoff date or outside of the data that it was trained on.
You can see this limitation with a simple example:
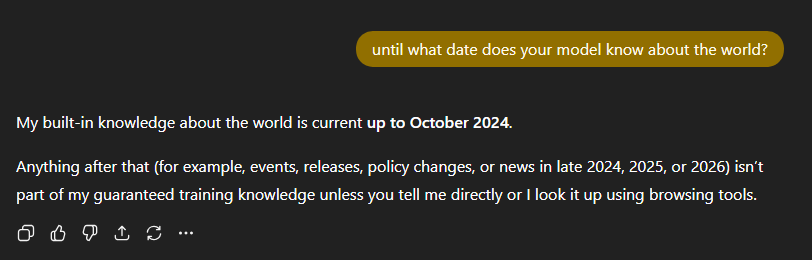
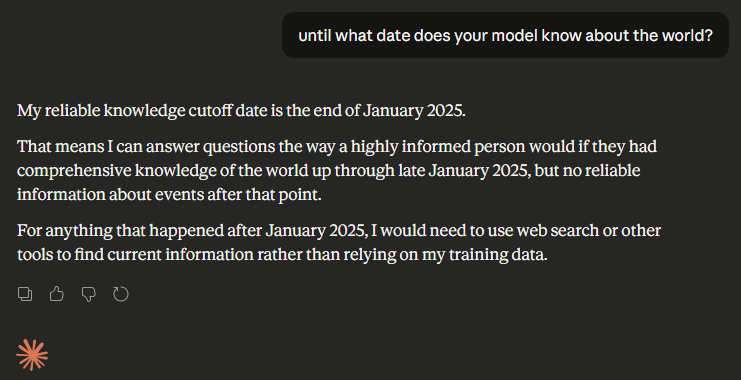
This is where things go off the rails. People notice that AI systems can answer questions about recent events or live systems. From the outside, it looks like continuous learning and actual up-to-date knowledge. What’s actually happening is the model’s data is being augmented. The model itself hasn’t learned anything new. It’s been given access to external information and asked to reason over it.
Most real-world systems do this through retrieval‑augmented generation, or RAG. A query comes in, relevant documents or records are retrieved from a database, a search engine, or an API, and those results are injected into the model’s context window. The model then operates on all the data and comes up with an answer based on that material. When it works well, it feels like the model is suddenly intelligent and up-to-date. In reality, it’s just better informed in that moment.
All of this matters because it shifts the center of gravity away from the model, the idea of artificial intelligence, and toward the data. If the data is organized, structured, well‑labeled, and explicit about things like time, ownership, and authority, the model can do impressive work. It can connect dots across documents, explain why decisions were made, surface inconsistencies, and summarize complex systems faster than any human could.
If the data is not well organized, the failure mode is hallucinations because the models still answer the question, because answering is what the models are optimized to do. Accuracy is not guaranteed.
An LLM has no inherent understanding of what your data means. It doesn’t know which document is authoritative, which version is obsolete, even how the data was derived. Unless you encode those distinctions explicitly, the model will infer them. And inference, in this context, is just guesswork dressed up as confidence.
I’ll go through an e-commerce example below to demonstrate what I mean.
Once you stop treating an LLM like a knowledge store and start treating it like a reasoning engine sitting on top of your information architecture, the ideas will fall into place much easier. The model doesn’t save you from poor structure though, it magnifies it. Good data modeling, clear schemas, explicit metadata, and disciplined information hygiene don’t just make AI safer, they determine whether it’s useful at all.
This is why AI hasn’t reduced the importance of experienced engineers and technical leaders. Someone still has to decide what is true, what is current, what matters, and what must never be inferred. AI can help you explore the space faster. Humans are still responsible for deciding which parts of that space correspond to reality.
Here’s a very simplified e-commerce example that’ll help AI better answer questions about data.
Note, the below code is for MySQL/MariaDB.
Layer 0: Raw events
This is the raw layer. It may contain duplicates, messy data. This is the layer you want to be able to cite as source-of-truth.
Table definition + sample data
DROP TABLE IF EXISTS l0_raw_order_events;
CREATE TABLE l0_raw_order_events (
raw_event_id BIGINT PRIMARY KEY,
event_type VARCHAR(32) NOT NULL,
order_id VARCHAR(32) NOT NULL,
order_line_id VARCHAR(32) NOT NULL,
customer_id VARCHAR(32) NOT NULL,
product_sku_raw VARCHAR(64) NOT NULL,
quantity INT NOT NULL,
unit_price_cents INT NOT NULL,
event_ts DATE NOT NULL
);
INSERT INTO l0_raw_order_events VALUES
(1001, 'ORDER_PLACED', 'O-1', 'O-1-1', 'C-10', 'sku001', 2, 1500, '2026-02-10'),
(1002, 'ORDER_PLACED', 'O-1', 'O-1-1', 'C-10', 'SKU001', 2, 1500, '2026-02-10'), -- duplicate of 1001
(1003, 'ORDER_PLACED', 'O-2', 'O-2-1', 'C-10', 'SKU002', 1, 2500, '2026-02-11'),
(1004, 'REFUND_ISSUED', 'O-1', 'O-1-1', 'C-10', 'SKU001', 1, 1500, '2026-02-12'), -- partial refund
(1005, 'ORDER_PLACED', 'O-3', 'O-3-1', 'C-20', 'sku-003', 3, 800, '2026-02-12'); -- new customer + messy SKULayer 0 table (results)
| raw_event_id | event_type | order_id | order_line_id | customer_id | product_sku_raw | quantity | unit_price_cents | event_ts |
|---|---|---|---|---|---|---|---|---|
| 1001 | ORDER_PLACED | O-1 | O-1-1 | C-10 | sku001 | 2 | 1500 | 2026-02-10 |
| 1002 | ORDER_PLACED | O-1 | O-1-1 | C-10 | SKU001 | 2 | 1500 | 2026-02-10 |
| 1003 | ORDER_PLACED | O-2 | O-2-1 | C-10 | SKU002 | 1 | 2500 | 2026-02-11 |
| 1004 | REFUND_ISSUED | O-1 | O-1-1 | C-10 | SKU001 | 1 | 1500 | 2026-02-12 |
| 1005 | ORDER_PLACED | O-3 | O-3-1 | C-20 | sku-003 | 3 | 800 | 2026-02-12 |
Lineage at Layer 0
None. This is the source.
Layer 1: Cleaned event facts (normalized + deduped)
Layer 1 creates normalized data while staying close to the original events.
SQL to derive Layer 1 tables
DROP TABLE IF EXISTS l1_clean_order_events;
CREATE TABLE l1_clean_order_events (
l1_event_id BIGINT AUTO_INCREMENT PRIMARY KEY,
raw_event_id BIGINT NOT NULL,
order_id VARCHAR(32) NOT NULL,
order_line_id VARCHAR(32) NOT NULL,
customer_id VARCHAR(32) NOT NULL,
product_sku VARCHAR(64) NOT NULL,
qty INT NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
event_type VARCHAR(32) NOT NULL,
event_ts DATE NOT NULL
);
-- Lineage table L1 -> L0
DROP TABLE IF EXISTS lineage_l1_to_l0;
CREATE TABLE lineage_l1_to_l0 (
l1_event_id BIGINT NOT NULL,
raw_event_id BIGINT NOT NULL,
PRIMARY KEY (l1_event_id, raw_event_id)
);
-- Populate the normalized data (fix SKU names, deduplicate records, etc.
INSERT INTO l1_clean_order_events (
raw_event_id, order_id, order_line_id, customer_id, product_sku, qty, unit_price, event_type, event_ts
)
WITH normalized AS (
SELECT
raw_event_id,
order_id,
order_line_id,
customer_id,
REGEXP_REPLACE(UPPER(TRIM(product_sku_raw)), '[^A-Z0-9]', '') AS product_sku,
quantity AS qty,
CAST(unit_price_cents / 100.0 AS DECIMAL(10,2)) AS unit_price,
event_type,
event_ts,
ROW_NUMBER() OVER (
PARTITION BY
order_id, order_line_id, customer_id,
REGEXP_REPLACE(UPPER(TRIM(product_sku_raw)), '[^A-Z0-9]', ''),
quantity, unit_price_cents, event_type, event_ts
ORDER BY raw_event_id
) AS rn
FROM l0_raw_order_events
)
SELECT
raw_event_id, order_id, order_line_id, customer_id, product_sku, qty, unit_price, event_type, event_ts
FROM normalized
WHERE rn = 1;
-- Populate lineage using the raw_event_id we carried forward
INSERT INTO lineage_l1_to_l0 (l1_event_id, raw_event_id)
SELECT l1_event_id, raw_event_id
FROM l1_clean_order_events;Layer 1 table (results)
| l1_event_id | raw_event_id | order_id | order_line_id | customer_id | product_sku | qty | unit_price | event_type | event_ts |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1001 | O-1 | O-1-1 | C-10 | SKU001 | 2 | 15.00 | ORDER_PLACED | 2026-02-10 |
| 2 | 1003 | O-2 | O-2-1 | C-10 | SKU002 | 1 | 25.00 | ORDER_PLACED | 2026-02-11 |
| 3 | 1004 | O-1 | O-1-1 | C-10 | SKU001 | 1 | 15.00 | REFUND_ISSUED | 2026-02-12 |
| 4 | 1005 | O-3 | O-3-1 | C-20 | SKU003 | 3 | 8.00 | ORDER_PLACED | 2026-02-12 |
(Notice raw_event_id 1002 is removed by dedupe.)
Lineage: lineage_l1_to_l0 (results)
| l1_event_id | raw_event_id |
|---|---|
| 1 | 1001 |
| 2 | 1003 |
| 3 | 1004 |
| 4 | 1005 |
Layer 2: Analytics-ready net order lines (net revenue + net quantity)
Layer 2 is where the system becomes opinionated: it converts event-level reality (sales + refunds) into net business facts that dashboards and AI will ask about. This layer must be attributable because it is derived, aggregated truth.
SQL to derive Layer 2 tables
DROP TABLE IF EXISTS l2_order_line_net;
CREATE TABLE l2_order_line_net (
l2_line_id BIGINT AUTO_INCREMENT PRIMARY KEY,
order_id VARCHAR(32) NOT NULL,
order_line_id VARCHAR(32) NOT NULL,
customer_id VARCHAR(32) NOT NULL,
product_sku VARCHAR(64) NOT NULL,
net_qty INT NOT NULL,
net_revenue DECIMAL(12,2) NOT NULL,
effective_day DATE NOT NULL
);
-- Lineage table L2 -> L1
DROP TABLE IF EXISTS lineage_l2_to_l1;
CREATE TABLE lineage_l2_to_l1 (
l2_line_id BIGINT NOT NULL,
l1_event_id BIGINT NOT NULL,
contribution_type VARCHAR(16) NOT NULL, -- 'SALE' or 'REFUND'
PRIMARY KEY (l2_line_id, l1_event_id)
);
-- Derivation: aggregate by order line
-- These derivations can be anything, but it's important that you can attribute them back
INSERT INTO l2_order_line_net (order_id, order_line_id, customer_id, product_sku, net_qty, net_revenue, effective_day)
SELECT
order_id,
order_line_id,
customer_id,
product_sku,
SUM(CASE WHEN event_type='ORDER_PLACED' THEN qty
WHEN event_type='REFUND_ISSUED' THEN -qty
ELSE 0 END) AS net_qty,
SUM(CASE WHEN event_type='ORDER_PLACED' THEN qty*unit_price
WHEN event_type='REFUND_ISSUED' THEN -qty*unit_price
ELSE 0 END) AS net_revenue,
MAX(event_ts) AS effective_day
FROM l1_clean_order_events
GROUP BY order_id, order_line_id, customer_id, product_sku
ORDER BY order_id, order_line_id;
-- Populate lineage: map each L2 row back to contributing L1 rows
INSERT INTO lineage_l2_to_l1 (l2_line_id, l1_event_id, contribution_type)
SELECT
l2.l2_line_id,
l1.l1_event_id,
CASE WHEN l1.event_type='ORDER_PLACED' THEN 'SALE' ELSE 'REFUND' END
FROM l2_order_line_net l2
JOIN l1_clean_order_events l1
ON l1.order_id = l2.order_id
AND l1.order_line_id = l2.order_line_id
AND l1.customer_id = l2.customer_id
AND l1.product_sku = l2.product_sku;Layer 2 table (results)
| l2_line_id | order_id | order_line_id | customer_id | product_sku | net_qty | net_revenue | effective_day |
|---|---|---|---|---|---|---|---|
| 1 | O-1 | O-1-1 | C-10 | SKU001 | 1 | 15.00 | 2026-02-12 |
| 2 | O-2 | O-2-1 | C-10 | SKU002 | 1 | 25.00 | 2026-02-11 |
| 3 | O-3 | O-3-1 | C-20 | SKU003 | 3 | 24.00 | 2026-02-12 |
Lineage: lineage_l2_to_l1 (results)
| l2_line_id | l1_event_id | contribution_type |
|---|---|---|
| 1 | 1 | SALE |
| 1 | 3 | REFUND |
| 2 | 2 | SALE |
| 3 | 4 | SALE |
End-to-end lineage: Layer 2 → Layer 0 (final derived fact → original raw)
Even with only 3 layers, you still want an ability to attribute the final data back to the raw data, so an LLM can cite original records without walking multiple joins every time.
SQL to build end-to-end lineage
DROP TABLE IF EXISTS lineage_l2_to_l0;
CREATE TABLE lineage_l2_to_l0 (
l2_line_id BIGINT NOT NULL,
raw_event_id BIGINT NOT NULL,
PRIMARY KEY (l2_line_id, raw_event_id)
);
INSERT INTO lineage_l2_to_l0 (l2_line_id, raw_event_id)
SELECT DISTINCT
l2.l2_line_id,
l0.raw_event_id
FROM lineage_l2_to_l1 l2
JOIN lineage_l1_to_l0 l0
ON l0.l1_event_id = l2.l1_event_id;lineage_l2_to_l0 (results)
| l2_line_id | raw_event_id |
|---|---|
| 1 | 1001 |
| 1 | 1004 |
| 2 | 1003 |
| 3 | 1005 |
Meaning:
- Net line O-1/O-1-1 derived from raw events 1001 (sale) and 1004 (refund)
- Net line O-2/O-2-1 derived from raw event 1003 (sale)
- Net line O-3/O-3-1 derived from raw event 1005 (sale)
Meta Data Tables
These tables exist for machines, not humans.
ai_table_catalog
This is what you pass to the model so it can:
- discover tables
- understand the purpose and grain
- find primary keys and join keys
- know which tables are “source of truth”
- know which tables are safe for analytics vs raw
DROP TABLE IF EXISTS ai_table_catalog;
CREATE TABLE ai_table_catalog (
table_name VARCHAR(128) PRIMARY KEY,
layer VARCHAR(8) NOT NULL, -- L0, L1, L2
table_role VARCHAR(64) NOT NULL, -- 'raw', 'clean_facts', 'analytics'
description TEXT NOT NULL, -- human + AI-readable
grain VARCHAR(255) NOT NULL, -- e.g. 'one row per ingested event'
primary_key VARCHAR(255) NOT NULL, -- e.g. 'raw_event_id'
natural_key VARCHAR(512) NULL, -- useful for dedupe / uniqueness explanation
important_columns TEXT NOT NULL, -- short list of key columns and meaning
join_guidance TEXT NOT NULL, -- how to join to other tables
freshness_policy VARCHAR(255) NOT NULL, -- e.g. 'append-only daily'
authoritative_source TINYINT(1) NOT NULL DEFAULT 0, -- 1 if source-of-truth
pii_notes TEXT NULL, -- what to be careful about
query_examples TEXT NULL -- small examples agents can use
);INSERT INTO ai_table_catalog (
table_name, layer, table_role, description, grain, primary_key, natural_key,
important_columns, join_guidance, freshness_policy, authoritative_source, pii_notes, query_examples
) VALUES
(
'l0_raw_order_events','L0','raw',
'Raw order events exactly as ingested. Contains duplicates and inconsistent SKUs. Use for audit and citations.',
'One row per ingested event record (may include duplicates).',
'raw_event_id',
'order_id + order_line_id + customer_id + normalized product_sku + quantity + unit_price_cents + event_type + event_ts',
'raw_event_id (unique id), event_type (ORDER_PLACED/REFUND_ISSUED), order_id/order_line_id, customer_id, product_sku_raw (messy), quantity, unit_price_cents, event_ts',
'Prefer joining upward via lineage_l1_to_l0 rather than joining directly to L2; raw has duplicates.',
'Append-only; no updates expected.',
1,
'customer_id may be considered sensitive depending on org policy.',
'SELECT * FROM l0_raw_order_events WHERE order_id=''O-1'';'
),
(
'l1_clean_order_events','L1','clean_facts',
'Cleaned event-level facts derived from L0. SKUs normalized, duplicates removed. Each row maps to exactly one representative raw_event_id.',
'One row per deduplicated event fact.',
'l1_event_id',
'order_id + order_line_id + customer_id + product_sku + qty + unit_price + event_type + event_ts',
'l1_event_id (surrogate PK), raw_event_id (pointer to source), product_sku (normalized), qty, unit_price, event_type, event_ts',
'Join to L0 through lineage_l1_to_l0. Join to L2 through lineage_l2_to_l1 or by (order_id, order_line_id, customer_id, product_sku).',
'Rebuilt from L0; deterministic dedupe.',
0,
'customer_id may be considered sensitive depending on org policy.',
'SELECT * FROM l1_clean_order_events WHERE customer_id=''C-10'' ORDER BY event_ts;'
),
(
'l2_order_line_net','L2','analytics',
'Net order-line facts for analytics. Sales and refunds combined into net_qty and net_revenue.',
'One row per (order_id, order_line_id, customer_id, product_sku).',
'l2_line_id',
'order_id + order_line_id + customer_id + product_sku',
'net_qty (sales-refunds), net_revenue (signed revenue), effective_day (max event_ts for the line)',
'Trace back to contributing events via lineage_l2_to_l1, and all the way to raw via lineage_l2_to_l0.',
'Rebuilt from L1; deterministic aggregation.',
0,
'customer_id may be considered sensitive depending on org policy.',
'SELECT * FROM l2_order_line_net WHERE effective_day=''2026-02-12'';'
);ai_column_catalog
This gives an agent column-level semantics without reading schema DDL.
DROP TABLE IF EXISTS ai_column_catalog;
CREATE TABLE ai_column_catalog (
table_name VARCHAR(128) NOT NULL,
column_name VARCHAR(128) NOT NULL,
data_type VARCHAR(64) NOT NULL,
description TEXT NOT NULL,
semantic_type VARCHAR(64) NOT NULL, -- 'id', 'timestamp', 'money', 'quantity', 'category', etc.
is_primary_key TINYINT(1) NOT NULL DEFAULT 0,
is_foreign_key TINYINT(1) NOT NULL DEFAULT 0,
fk_table VARCHAR(128) NULL,
fk_column VARCHAR(128) NULL,
example_values TEXT NULL,
PRIMARY KEY (table_name, column_name)
);INSERT INTO ai_column_catalog VALUES
('l2_order_line_net','l2_line_id','BIGINT','Surrogate primary key for net order-line row.','id',1,0,NULL,NULL,'1,2,3'),
('l2_order_line_net','order_id','VARCHAR(32)','Order identifier from commerce system.','id',0,0,NULL,NULL,'O-1,O-2'),
('l2_order_line_net','order_line_id','VARCHAR(32)','Order line identifier within an order.','id',0,0,NULL,NULL,'O-1-1'),
('l2_order_line_net','customer_id','VARCHAR(32)','Customer identifier (may be PII depending on org policy).','id',0,0,NULL,NULL,'C-10,C-20'),
('l2_order_line_net','product_sku','VARCHAR(64)','Normalized product SKU (uppercase, alphanumeric).','id',0,0,NULL,NULL,'SKU001,SKU002'),
('l2_order_line_net','net_qty','INT','Net quantity = sales quantity minus refunded quantity.','quantity',0,0,NULL,NULL,'1,3'),
('l2_order_line_net','net_revenue','DECIMAL(12,2)','Net revenue = sum(qty*unit_price) with refunds treated as negative.','money',0,0,NULL,NULL,'15.00,24.00'),
('l2_order_line_net','effective_day','DATE','Effective day for the net line (MAX(event_ts) from contributing events).','date',0,0,NULL,NULL,'2026-02-11,2026-02-12');ai_lineage_catalog
DROP TABLE IF EXISTS ai_lineage_catalog;
CREATE TABLE ai_lineage_catalog (
lineage_table_name VARCHAR(128) PRIMARY KEY,
from_table_name VARCHAR(128) NOT NULL,
to_table_name VARCHAR(128) NOT NULL,
from_key_column VARCHAR(128) NOT NULL,
to_key_column VARCHAR(128) NOT NULL,
relationship VARCHAR(64) NOT NULL, -- 'many-to-many', 'many-to-one', etc.
description TEXT NOT NULL,
query_example TEXT NULL
);INSERT INTO ai_lineage_catalog VALUES
(
'lineage_l1_to_l0',
'l1_clean_order_events',
'l0_raw_order_events',
'l1_event_id',
'raw_event_id',
'many-to-one',
'Maps each cleaned event (L1) to the representative raw event (L0) it came from.',
'SELECT l0.* FROM lineage_l1_to_l0 x JOIN l0_raw_order_events l0 ON l0.raw_event_id=x.raw_event_id WHERE x.l1_event_id=1;'
),
(
'lineage_l2_to_l1',
'l2_order_line_net',
'l1_clean_order_events',
'l2_line_id',
'l1_event_id',
'many-to-many',
'Maps each net order-line (L2) to the contributing cleaned events (L1). Includes contribution_type (SALE/REFUND).',
'SELECT l1.*, x.contribution_type FROM lineage_l2_to_l1 x JOIN l1_clean_order_events l1 ON l1.l1_event_id=x.l1_event_id WHERE x.l2_line_id=1;'
),
(
'lineage_l2_to_l0',
'l2_order_line_net',
'l0_raw_order_events',
'l2_line_id',
'raw_event_id',
'many-to-many',
'End-to-end mapping from net order-line (L2) directly to raw events (L0) for citations and audit.',
'SELECT l0.* FROM lineage_l2_to_l0 x JOIN l0_raw_order_events l0 ON l0.raw_event_id=x.raw_event_id WHERE x.l2_line_id=1;'
);lineage_transform_meta
DROP TABLE IF EXISTS lineage_transform_meta;
CREATE TABLE lineage_transform_meta (
transform_id VARCHAR(32) PRIMARY KEY,
from_table VARCHAR(128) NOT NULL,
to_table VARCHAR(128) NOT NULL,
description VARCHAR(255) NOT NULL,
logic_summary TEXT NOT NULL,
version VARCHAR(16) NOT NULL,
updated_at DATETIME NOT NULL
);
INSERT INTO lineage_transform_meta VALUES
('L1_CLEAN','l0_raw_order_events','l1_clean_order_events',
'Normalize and deduplicate raw events',
'Normalize SKU (UPPER/TRIM/strip non-alphanumeric); dedupe by natural key using ROW_NUMBER; convert cents->dollars; keep representative raw_event_id for citation.',
'v1.0','2026-02-14 00:00:00'),
('L2_NET','l1_clean_order_events','l2_order_line_net',
'Compute net qty and net revenue per order line',
'Aggregate by (order_id, order_line_id, customer_id, product_sku). Treat refunds as negative. effective_day = MAX(event_ts). Populate lineage_l2_to_l1 and lineage_l2_to_l0 for traceability.',
'v1.0','2026-02-14 00:00:00');Next Steps + Example
From this point, creating AI code that can read the metadata and decide on how to query the data is a pretty straight forward process of feeding in the ai_* tables as system prompts and asking it to create SQL queries to fetch data as it needs. Executing those SQL continuously (within limits) as long as the AI wants to keep exploring can also easily be coded.
Here are two example questions:
Question 1: How do you think the data in L2 was derived from L0?
Answer 1: L2 represents net business outcomes aggregated from cleaned L1 events, which themselves are normalized and deduplicated versions of raw L0 data.
Question 2: give me the lineage of O-1 from L2 to L0?
Answer 2: L2 O-1 is derived from one cleaned sale event and one cleaned refund event in L1, which trace back to raw events 1001 and 1004 in L0, producing:
net_qty = 2 − 1 = 1
net_revenue = 30 − 15 = 15
All that’s to say, doing the work upfront with data makes the LLM side of things significantly easier.