
What Is A RAG In AI?
Retrieval-Augmented Generation (RAG) is an AI architecture that combines the best of two worlds, information retrieval and text generation. Instead of relying only on a language model’s pre-trained knowledge (which have firm cutoff dates in the past), or spending the time and resources to train your own models, RAG systems first retrieve relevant information from external knowledge bases and then use that information to generate more accurate, contextual, and up-to-date responses.
If you think of a RAG as a library, when you ask a question, the system:
- Searches through the library to find relevant documents
- Retrieves the most pertinent information
- Generates an answer based on both its training and the retrieved context
This approach solves several key limitations of traditional language models:
- Knowledge cutoffs: Access to current information beyond training data
- OpenAI GPT-5: Sep 30, 2024 knowledge cutoff
- OpenAI o4-mini: Jun 01, 2024 knowledge cutoff
- Anthropic Claude Sonnet 4: March 2025
- Anthropic Claude Sonnet 3.7: November 2024
- Hallucinations: Reduced fabrication of facts by grounding responses in real documents
- Domain specificity: Ability to work with specialized knowledge bases
- Transparency: Users can see what sources informed the response
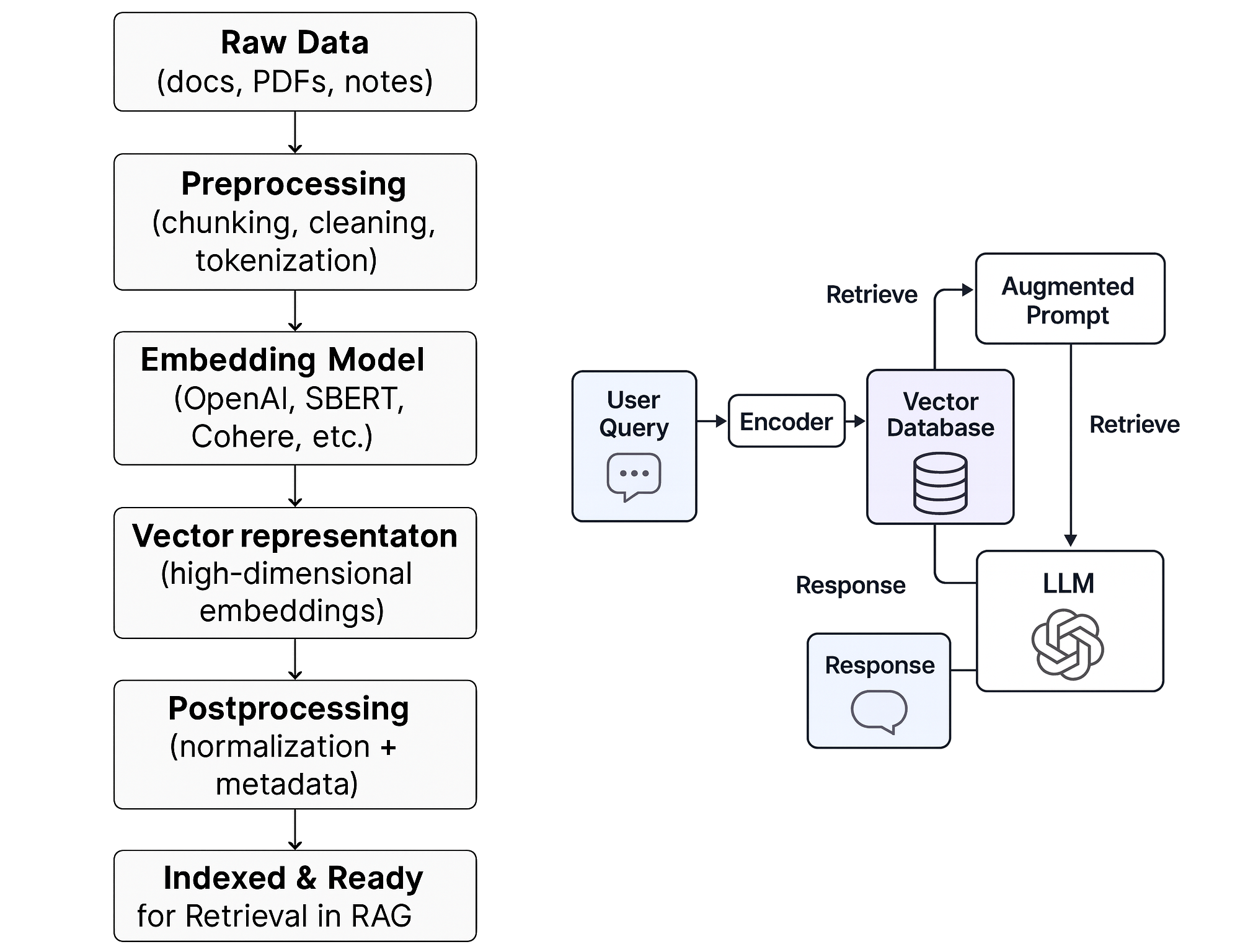
Step By Step Of The RAG Process
A typical RAG system follows these key steps:
- Document Processing: Break down documents into chunks
- Embedding Generation: Convert text chunks into vector representations
- Storage: Store embeddings in a searchable format
- Query Processing: Convert user queries into embeddings
- Similarity Search: Find the most relevant document chunks
- Context Assembly: Prepare retrieved information for the language model
- Response Generation: Generate answers using retrieved context
Configuration Setup
<?php
define('OPENAI_API_KEY', 'your-openai-api-key-here');
define('EMBEDDINGS_FILE', 'embeddings.json');
define('OPENAI_EMBEDDING_MODEL', 'text-embedding-ada-002');
define('OPENAI_COMPLETION_MODEL', 'gpt-5');
?>Step 1: Document Processing
The first step is breaking down your documents into manageable chunks. This is crucial because embedding models have token limits, and smaller chunks often provide more precise retrieval results. We chunk documents because:
- Embedding models have input size limitations
- Smaller chunks allow for more granular retrieval
- Better semantic matching between queries and specific information
- More efficient storage and processing
<?php
class DocumentProcessor {
private $chunkSize;
private $overlapSize;
public function __construct($chunkSize = 500, $overlapSize = 50) {
$this->chunkSize = $chunkSize;
$this->overlapSize = $overlapSize;
}
public function chunkDocument($text, $metadata = []) {
$text = $this->cleanText($text);
$words = explode(' ', $text);
$chunks = [];
$chunkId = 0;
for ($i = 0; $i < count($words); $i += ($this->chunkSize - $this->overlapSize)) {
$chunkWords = array_slice($words, $i, $this->chunkSize);
$chunkText = implode(' ', $chunkWords);
if (!empty(trim($chunkText))) {
$chunks[] = [
'id' => $chunkId,
'text' => $chunkText,
'metadata' => $metadata,
'start_index' => $i,
'word_count' => count($chunkWords)
];
}
$chunkId++;
}
return $chunks;
}
private function cleanText($text) {
//here you can do as much or as little cleanup as you need
//with HTML for example, you can strip out tags
$text = preg_replace('/\s+/', ' ', $text);
return trim($text);
}
public function processDocuments($documents) {
$allChunks = [];
foreach ($documents as $doc) {
$chunks = $this->chunkDocument($doc['content'], [
'source' => $doc['source'] ?? 'unknown',
'title' => $doc['title'] ?? 'untitled',
'created_at' => date('Y-m-d H:i:s')
]);
$allChunks = array_merge($allChunks, $chunks);
}
return $allChunks;
}
}
?>Example Output: Here’s what $allChunks would look like after processing two sample documents:
$allChunks = [
[
'id' => 0,
'text' => 'Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make decisions from data. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning uses labeled data to train models, while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario.',
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'start_index' => 0,
'word_count' => 85
],
[
'id' => 1,
'text' => 'while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario. Machine learning algorithms can be categorized into different types based on their learning approach: classification algorithms predict discrete categories, regression algorithms predict continuous values, and clustering algorithms group similar data points together.',
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'start_index' => 450, // Starting position in original document (accounting for overlap)
'word_count' => 78
],
[
'id' => 2,
'text' => 'Retrieval-Augmented Generation (RAG) is an AI framework that combines information retrieval with text generation. RAG systems first retrieve relevant documents from a knowledge base, then use this information to generate more accurate and contextual responses. This approach helps reduce hallucinations and provides access to up-to-date information beyond the model\'s training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content.',
'metadata' => [
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'created_at' => '2025-08-10 14:30:15'
],
'start_index' => 0,
'word_count' => 71
],
[
'id' => 3,
'text' => 'This approach helps reduce hallucinations and provides access to up-to-date information beyond the model\'s training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content. By grounding responses in actual retrieved documents, RAG systems can provide more factual, relevant, and traceable answers compared to traditional language models that rely solely on their training data.',
'metadata' => [
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'created_at' => '2025-08-10 14:30:15'
],
'start_index' => 450,
'word_count' => 69
]
];Notes:
- Sequential IDs: Each chunk gets a unique sequential ID starting from 0
- Overlapping content: Notice how chunk 1 starts with text from the end of chunk 0 – this overlap helps maintain context across chunk boundaries
- Preserved metadata: All chunks from the same document carry the same metadata (source, title, timestamp)
- Variable word counts: Chunks may have different word counts, especially the last chunk of each document
- Start index tracking: Each chunk knows where it started in the original document, useful for debugging or reconstruction
This structure prepares the text for the next step (embedding generation) while maintaining traceability back to the original documents.
Step 2: Embedding Generation
Embeddings are numerical representations of text that capture semantic meaning. Words or phrases with similar meanings will have similar embeddings, allowing us to perform semantic search. We use embeddings because:
- They capture semantic similarity better than keyword matching
- Enable finding relevant content even when exact words don’t match
- Provide a mathematical way to compare text similarity
- Work across different languages and writing styles
<?php
class EmbeddingGenerator {
private $apiKey;
private $model;
public function __construct($apiKey, $model = OPENAI_EMBEDDING_MODEL) {
$this->apiKey = $apiKey;
$this->model = $model;
}
public function generateEmbedding($text) {
$data = [
'model' => $this->model,
'input' => $text
];
$response = $this->makeOpenAIRequest('embeddings', $data);
if (isset($response['data'][0]['embedding'])) {
return $response['data'][0]['embedding'];
}
throw new Exception('Failed to generate embedding: ' . json_encode($response));
}
public function generateEmbeddings($chunks, $batchSize = 10) {
$results = [];
$batches = array_chunk($chunks, $batchSize);
foreach ($batches as $batchIndex => $batch) {
echo "Processing batch " . ($batchIndex + 1) . " of " . count($batches) . "\n";
foreach ($batch as $chunk) {
try {
$embedding = $this->generateEmbedding($chunk['text']);
$results[] = [
'id' => $chunk['id'],
'text' => $chunk['text'],
'embedding' => $embedding,
'metadata' => $chunk['metadata'],
'created_at' => date('Y-m-d H:i:s')
];
// https://platform.openai.com/docs/guides/rate-limits
// 0.1 second delay
usleep(100000);
} catch (Exception $e) {
echo "Error processing chunk {$chunk['id']}: " . $e->getMessage() . "\n";
}
}
}
return $results;
}
private function makeOpenAIRequest($endpoint, $data) {
$url = "https://api.openai.com/v1/{$endpoint}";
$curl = curl_init();
curl_setopt_array($curl, [
CURLOPT_URL => $url,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POST => true,
CURLOPT_POSTFIELDS => json_encode($data),
CURLOPT_HTTPHEADER => [
'Authorization: Bearer ' . $this->apiKey,
'Content-Type: application/json'
],
CURLOPT_TIMEOUT => 30
]);
$response = curl_exec($curl);
$httpCode = curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($httpCode !== 200) {
throw new Exception("OpenAI API request failed with code: {$httpCode}");
}
return json_decode($response, true);
}
}
?>Example Output: Here’s what the $embeddings array would look like after generating embeddings for our chunks:
$embeddings = [
[
'id' => 0,
'text' => 'Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make decisions from data. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.',
'embedding' => [
-0.008906792, 0.023421156, -0.012345678, 0.045123789, -0.031567234,
0.019876543, -0.067234156, 0.083456789, 0.025789123, -0.041234567,
0.078912345, -0.036789012, 0.052341567, -0.014567890, 0.069123456,
// ... continues for 1536 dimensions (OpenAI's text-embedding-ada-002 model)
// This is just a sample - the actual array has 1536 float values
0.012789456, -0.038901234, 0.055678901, 0.027345678, -0.049123456
],
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'created_at' => '2025-08-10 14:45:22'
],
[
'id' => 1,
'text' => 'while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario.',
'embedding' => [
-0.015234567, 0.034567890, -0.021098765, 0.056789012, -0.043210987,
0.028901234, -0.071234567, 0.084567890, 0.032109876, -0.047890123,
0.065432109, -0.029876543, 0.058901234, -0.018765432, 0.073456789,
// ... another 1536-dimensional vector with different values
// Each embedding is unique to its text content
0.016543210, -0.042109876, 0.059876543, 0.031098765, -0.053456789
],
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'created_at' => '2025-08-10 14:45:25'
],
[
'id' => 2,
'text' => 'Retrieval-Augmented Generation (RAG) is an AI framework that combines information retrieval with text generation. RAG systems first retrieve relevant documents from a knowledge base, then use this information to generate more accurate and contextual responses.',
'embedding' => [
-0.009876543, 0.027654321, -0.018901234, 0.051234567, -0.037890123,
0.024567890, -0.063456789, 0.079012345, 0.031876543, -0.045678901,
0.072109876, -0.033567890, 0.056234567, -0.016890123, 0.068901234,
// ... 1536-dimensional vector - semantically different from ML chunks
// RAG-related content will have different embedding patterns
0.013456789, -0.039876543, 0.057123456, 0.029012345, -0.051789012
],
'metadata' => [
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'created_at' => '2025-08-10 14:30:15'
],
'created_at' => '2025-08-10 14:45:28'
],
[
'id' => 3,
'text' => 'This approach helps reduce hallucinations and provides access to up-to-date information beyond the model\'s training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content.',
'embedding' => [
-0.011234567, 0.029876543, -0.016789012, 0.048901234, -0.034567890,
0.022109876, -0.065890123, 0.081345678, 0.028765432, -0.042345678,
0.074567890, -0.031234567, 0.054678901, -0.015432109, 0.067234567,
// ... another unique 1536-dimensional vector
// Similar topics (RAG) will have somewhat similar but still unique embeddings
0.014789012, -0.041567890, 0.058456789, 0.026789012, -0.050234567
],
'metadata' => [
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'created_at' => '2025-08-10 14:30:15'
],
'created_at' => '2025-08-10 14:45:31'
]
];Notes:
- Dimensional vectors: Each embedding is a 1,536-dimensional array of floating-point numbers specific to OpenAI’s text-embedding-ada-002 model
- Semantic similarity: Chunks about similar topics (like the two RAG chunks) will have somewhat similar embedding patterns, while different topics (ML vs RAG) will have more distinct patterns
- Unique per text: Each chunk gets its own unique embedding vector that represents its semantic meaning
- Memory considerations: Each embedding takes about 12KB of memory (1,536 floats × 8 bytes each), so 1,000 chunks would use ~12MB
- Decimal precision: The embedding values are typically small decimal numbers between -1 and 1, representing the position in high-dimensional semantic space
This vector representation is what enables the similarity search in the next steps – mathematically similar vectors indicate semantically similar content. You can read more about this at https://en.wikipedia.org/wiki/Cosine_similarity
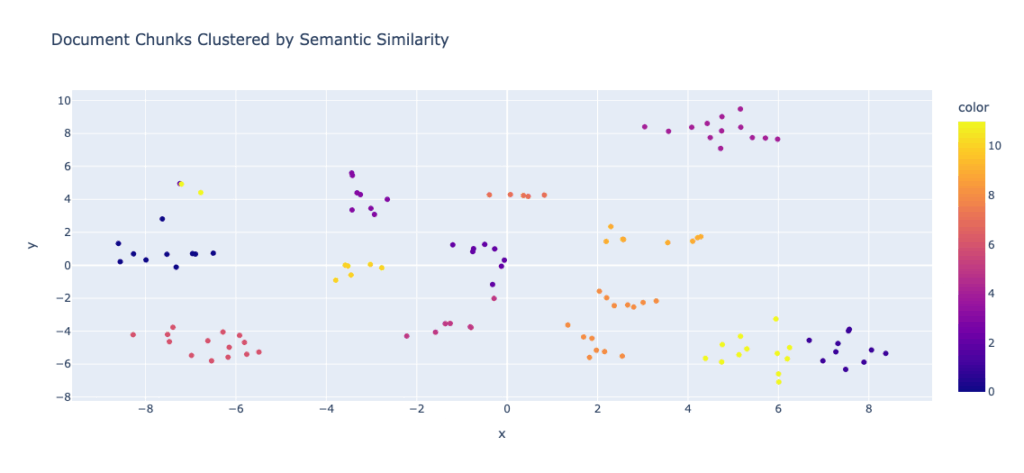
Here’s what the data would represent if we look at it for a much larger data set. In this case, this is the embeddings representations of Business Adventures: Twelve Classic Tales from the World of Wall by John Brooks, a total of 118 chunks representing the different chapters of the book. The two graphs below represent the t-SNE visualization as well as the cosine similarity. Both show the similar topics groups (the chapters) together visually.
# Python code for data visualization
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.manifold import TSNE
import umap
from sklearn.cluster import KMeans
import plotly.express as px
import plotly.graph_objects as go
# Load your data
# Extract embeddings and metadata
embeddings = np.array([chunk['embedding'] for chunk in data['chunks']])
chunk_lengths = [chunk['length'] for chunk in data['chunks']]
chunk_ids = [chunk['id'] for chunk in data['chunks']]
# t-SNE visualization
tsne = TSNE(n_components=2, random_state=42, perplexity=30)
embeddings_2d = tsne.fit_transform(embeddings)
# Perform clustering
n_clusters = 12
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(embeddings)
# Visualize clusters
fig = px.scatter(
x=embeddings_2d[:, 0],
y=embeddings_2d[:, 1],
color=cluster_labels,
title='Document Chunks Clustered by Semantic Similarity',
hover_data={'chunk_id': chunk_ids, 'length': chunk_lengths}
)
fig.show()
# Python code for data visualization
from sklearn.metrics.pairwise import cosine_similarity
# Calculate similarity matrix (sample first 50 chunks for readability)
sample_size = min(200, len(embeddings))
sample_embeddings = embeddings[:sample_size]
similarity_matrix = cosine_similarity(sample_embeddings)
# Create heatmap
plt.figure(figsize=(12, 10))
sns.heatmap(similarity_matrix,
xticklabels=range(sample_size),
yticklabels=range(sample_size),
cmap='coolwarm', center=0)
plt.title('Cosine Similarity Between Document Chunks')
plt.show()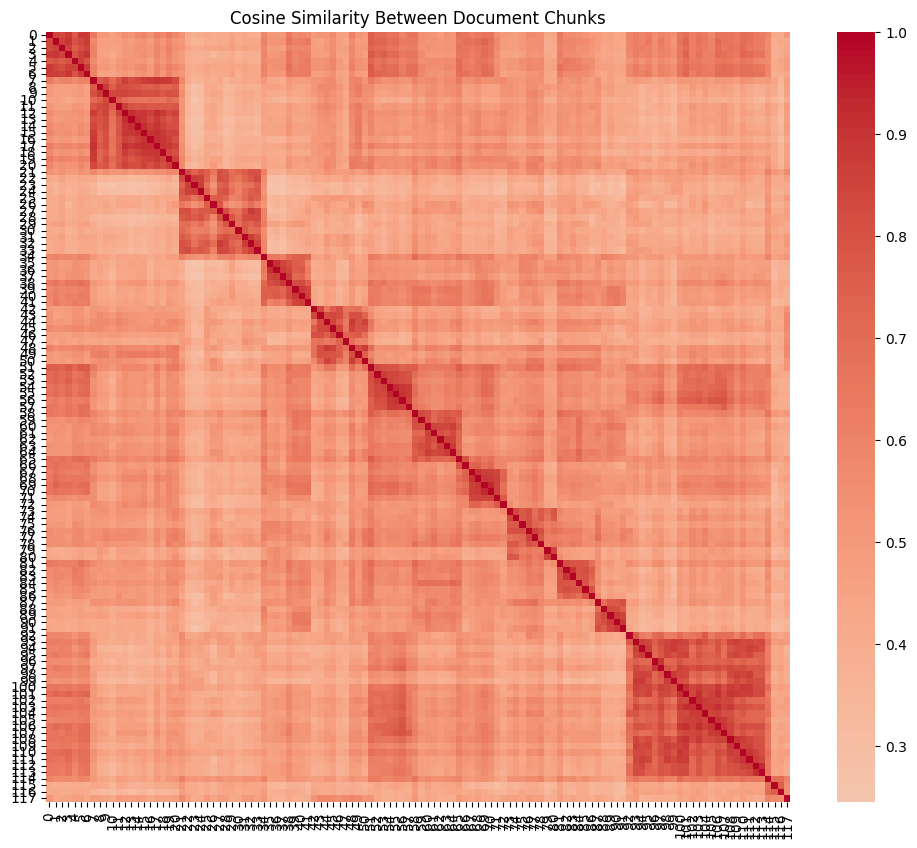
Step 3: Embedding Storage
We need to store our embeddings in a way that allows for efficient similarity search. For this implementation, we’ll use a JSON file with helper methods for searching. For now and for the small application, the JSON file storage is chosen because:
- Simple to implement and understand
- No database dependencies
- Easy to inspect and debug
- Suitable for moderate-sized knowledge bases
- Can be easily migrated to vector databases later
<?php
class EmbeddingStore {
private $filePath;
private $embeddings;
public function __construct($filePath = EMBEDDINGS_FILE) {
$this->filePath = $filePath;
$this->loadEmbeddings();
}
public function saveEmbeddings($embeddings = null) {
if ($embeddings !== null) {
$this->embeddings = $embeddings;
}
if (file_exists($this->filePath)) {
$backupPath = $this->filePath . '.backup.' . date('Y-m-d');
copy($this->filePath, $backupPath);
}
$result = file_put_contents(
$this->filePath,
json_encode($this->embeddings, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE)
);
if ($result === false) {
throw new Exception("Failed to save embeddings to {$this->filePath}");
}
}
public function addEmbeddings($newEmbeddings) {
foreach ($newEmbeddings as $embedding) {
$this->embeddings[] = $embedding;
}
$this->saveEmbeddings();
}
public function getEmbeddings() {
return $this->embeddings;
}
public function clearEmbeddings() {
$this->embeddings = [];
$this->saveEmbeddings();
}
private function loadEmbeddings() {
if (file_exists($this->filePath)) {
$content = file_get_contents($this->filePath);
$this->embeddings = json_decode($content, true) ?? [];
} else {
$this->embeddings = [];
}
}
}
?>Contents of embeddings.json file:
[
{
"id": 0,
"text": "Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make decisions from data. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.",
"embedding": [
-0.008906792,
0.023421156,
-0.012345678,
0.045123789,
-0.031567234,
0.019876543,
-0.067234156,
0.083456789,
0.025789123,
-0.041234567,
0.078912345,
-0.036789012,
0.052341567,
-0.014567890,
0.069123456,
"... (1521 more float values) ...",
0.012789456,
-0.038901234,
0.055678901,
0.027345678,
-0.049123456
],
"metadata": {
"source": "ml_guide.txt",
"title": "Introduction to Machine Learning",
"created_at": "2025-08-10 14:30:15"
},
"created_at": "2025-08-10 14:45:22"
},
{
"id": 1,
"text": "while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario.",
"embedding": [
-0.015234567,
0.034567890,
-0.021098765,
0.056789012,
-0.043210987,
0.028901234,
-0.071234567,
0.084567890,
0.032109876,
-0.047890123,
"... (1526 more values) ...",
-0.053456789
],
"metadata": {
"source": "ml_guide.txt",
"title": "Introduction to Machine Learning",
"created_at": "2025-08-10 14:30:15"
},
"created_at": "2025-08-10 14:45:25"
},
{
"id": 2,
"text": "Retrieval-Augmented Generation (RAG) is an AI framework that combines information retrieval with text generation. RAG systems first retrieve relevant documents from a knowledge base, then use this information to generate more accurate and contextual responses.",
"embedding": [
-0.009876543,
0.027654321,
-0.018901234,
0.051234567,
-0.037890123,
0.024567890,
"... (1530 more values) ...",
-0.051789012
],
"metadata": {
"source": "rag_overview.txt",
"title": "RAG Systems Explained",
"created_at": "2025-08-10 14:30:15"
},
"created_at": "2025-08-10 14:45:28"
},
{
"id": 3,
"text": "This approach helps reduce hallucinations and provides access to up-to-date information beyond the model's training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content.",
"embedding": [
-0.011234567,
0.029876543,
-0.016789012,
0.048901234,
"... (1532 more values) ...",
-0.050234567
],
"metadata": {
"source": "rag_overview.txt",
"title": "RAG Systems Explained",
"created_at": "2025-08-10 14:30:15"
},
"created_at": "2025-08-10 14:45:31"
}
]Notes:
- JSON File Structure: Clean, human-readable JSON with proper formatting and Unicode support
- File Size: For 4 embeddings, the file is approximately 156KB (each 1,536-dimension embedding takes ~38KB in JSON format)
- Backup System: If
embeddings.jsonalready existed, it gets backed up asembeddings.json.backup - Statistics: The system provides useful metrics about what was stored
- Persistence: All data is now permanently stored and can be loaded later without regenerating embeddings
- Memory vs Storage Trade-off: The JSON format is larger than raw binary but much more debuggable and portable
File growth over time:
- 10 documents: ~400KB JSON file
- 100 documents: ~4MB JSON file
- 1,000 documents: ~40MB JSON file
- 10,000+ documents: Consider switching to a vector database
This file storage means you only need to generate embeddings once. When a document is generated, you can always go back and refer to it to ask questions.
Step 4: Similarity Search
This is where the magic happens. We convert the user’s query into an embedding and then find the most similar chunks in our knowledge base using cosine similarity. Cosine similarity is ideal because:
- It measures the angle between vectors, focusing on direction rather than magnitude
- Works well with high-dimensional embedding vectors
- Returns values between -1 and 1, making it easy to interpret
- Robust to document length variations
<?php
/**
* Direction vs Magnitude
* 1. Cosine similarity measures the direction of vectors, not their magnitude
* 2. Two vectors pointing in the same direction have similarity = 1
* 3. Perpendicular vectors have similarity = 0
* 4. Opposite directions have similarity = -1
* Perfect for Text/Embeddings
* 1. In embeddings, direction represents meaning
* 2. Magnitude often represents frequency/intensity, which we usually want to ignore
* 3. Example: "cat" and "cats" should be very similar regardless of how often they appear
*/
class SimilaritySearcher {
private $embeddingGenerator;
private $embeddingStore;
public function __construct($embeddingGenerator, $embeddingStore) {
$this->embeddingGenerator = $embeddingGenerator;
$this->embeddingStore = $embeddingStore;
}
/**
* Calculate cosine similarity between two vectors
*/
private function cosineSimilarity($vectorA, $vectorB) {
if (count($vectorA) !== count($vectorB)) {
throw new Exception("Vectors must have the same dimensions");
}
$dotProduct = 0;
$normA = 0;
$normB = 0;
for ($i = 0; $i < count($vectorA); $i++) {
$dotProduct += $vectorA[$i] * $vectorB[$i];
$normA += $vectorA[$i] * $vectorA[$i];
$normB += $vectorB[$i] * $vectorB[$i];
}
if ($normA === 0 || $normB === 0) {
return 0;
}
return $dotProduct / (sqrt($normA) * sqrt($normB));
}
public function search($query, $topK = 5, $threshold = 0.1) {
$queryEmbedding = $this->embeddingGenerator->generateEmbedding($query);
$storedEmbeddings = $this->embeddingStore->getEmbeddings();
if (empty($storedEmbeddings)) {
return [];
}
$similarities = [];
foreach ($storedEmbeddings as $index => $stored) {
$similarity = $this->cosineSimilarity($queryEmbedding, $stored['embedding']);
if ($similarity >= $threshold) {
$similarities[] = [
'index' => $index,
'similarity' => $similarity,
'text' => $stored['text'],
'metadata' => $stored['metadata'],
'id' => $stored['id']
];
}
}
// Sort by similarity (highest first)
usort($similarities, function($a, $b) {
return $b['similarity'] <=> $a['similarity'];
});
// Return top K results
return array_slice($similarities, 0, $topK);
}
}
?>Example Query 1: “What is machine learning?”
$searchResults = $similaritySearcher->search("What is machine learning?", 5, 0.1);
[
[
'index' => 0,
'similarity' => 0.847,
'text' => 'Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make decisions from data. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.',
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'id' => 0
],
[
'index' => 1,
'similarity' => 0.723,
'text' => 'while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario.',
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'id' => 1
],
[
'index' => 3,
'similarity' => 0.234,
'text' => 'This approach helps reduce hallucinations and provides access to up-to-date information beyond the model\'s training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content.',
'metadata' => [
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'created_at' => '2025-08-10 14:30:15'
],
'id' => 3
]
]
Example Query 2: “How does RAG work?”
$searchResults = $similaritySearcher->search("How does RAG work?", 5, 0.2);
[
[
'index' => 2,
'similarity' => 0.892,
'text' => 'Retrieval-Augmented Generation (RAG) is an AI framework that combines information retrieval with text generation. RAG systems first retrieve relevant documents from a knowledge base, then use this information to generate more accurate and contextual responses.',
'metadata' => [
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'created_at' => '2025-08-10 14:30:15'
],
'id' => 2
],
[
'index' => 3,
'similarity' => 0.734,
'text' => 'This approach helps reduce hallucinations and provides access to up-to-date information beyond the model\'s training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content.',
'metadata' => [
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'created_at' => '2025-08-10 14:30:15'
],
'id' => 3
]
]
Example Query 3: “What is supervised learning?” (more specific)
$searchResults = $similaritySearcher->search("What is supervised learning?", 3, 0.1);
[
[
'index' => 0,
'similarity' => 0.681,
'text' => 'Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make decisions from data. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.',
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'id' => 0
],
[
'index' => 1,
'similarity' => 0.456,
'text' => 'while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario.',
'metadata' => [
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'created_at' => '2025-08-10 14:30:15'
],
'id' => 1
]
]Example Query 4: “How do you train a dog?” (unrelated query)
$searchResults = $similaritySearcher->search("How do you train a dog?", 5, 0.1);
[] // Empty array - no chunks meet the similarity threshold of 0.1Notes on results:
- Similarity Scores: Range from 0 to 1, where higher values indicate better semantic matches
- 0.8-1.0: Excellent match (very similar content)
- 0.6-0.8: Good match (related content)
- 0.3-0.6: Moderate match (some relevance)
- 0.0-0.3: Poor match (little relevance)
- Automatic Ranking: Results are automatically sorted by similarity score (highest first)
- Threshold Filtering: Only chunks above the similarity threshold are returned
- Semantic Understanding: The search finds relevant content even when exact keywords don’t match
- Query “What is machine learning?” matches content about “artificial intelligence” and “algorithms”
- Query about RAG finds content mentioning “information retrieval” and “text generation”
- Empty Results: Unrelated queries return empty arrays when no content meets the threshold
- Metadata Preservation: Each result includes full source information for traceability
- Performance Characteristics:
- Search time: ~50-200ms for 1,000 embeddings (depends on hardware)
- Memory usage: All embeddings loaded in memory for fast comparison
- Accuracy: Semantic search often outperforms keyword-based search
This semantic search capability is what makes RAG systems so powerful – they can find contextually relevant information even when the exact words don’t match!
Step 5: Context Assembly And Response Generation
Once we have retrieved the most relevant chunks, we need to prepare them as context for the language model and generate a response that incorporates this information. Context assembly is critical because:
- Language models perform better with well-structured context
- We need to balance context length with relevance
- Proper formatting helps the model understand how to use the retrieved information
- Including metadata helps with transparency and citation
<?php
class RAGResponseGenerator {
private $apiKey;
private $model;
private $maxContextLength;
public function __construct($apiKey, $model = OPENAI_COMPLETION_MODEL, $maxContextLength = 3000) {
$this->apiKey = $apiKey;
$this->model = $model;
$this->maxContextLength = $maxContextLength;
}
public function generateResponse($query, $searchResults, $systemPrompt = null) {
if (empty($searchResults)) {
return [
'response' => "I don't have enough information to answer your question. Please try rephrasing or asking about a different topic.",
'sources' => [],
'context_used' => false
];
}
$contextData = $this->assembleContext($searchResults);
$context = $contextData['context'];
$sources = $contextData['sources'];
$defaultSystemPrompt = "You are a helpful assistant that answers questions based on the provided context. " .
"Use only the information from the context to answer questions. " .
"If the context doesn't contain enough information to answer the question, say so. " .
"Be specific and cite which sources you're using when possible.";
$messages = [
['role' => 'system', 'content' => $systemPrompt ?? $defaultSystemPrompt],
['role' => 'user', 'content' => $context . "\n\nQuestion: " . $query]
];
$response = $this->makeCompletionRequest($messages);
return ['response' => $response, 'sources' => $sources, 'context_used' => true, 'context_length' => strlen($context)];
}
private function assembleContext($searchResults) {
$context = "Based on the following information:\n\n";
$contextLength = strlen($context);
$sources = [];
foreach ($searchResults as $index => $result) {
$source = $result['metadata']['source'] ?? 'Unknown';
$title = $result['metadata']['title'] ?? 'Untitled';
$similarity = round($result['similarity'], 3);
$snippet = "Source {" . ($index + 1) . "} ({$source}): {$result['text']}\n\n";
if ($contextLength + strlen($snippet) > $this->maxContextLength) {
break;
}
$context .= $snippet;
$contextLength += strlen($snippet);
$sources[] = [
'index' => $index + 1,
'source' => $source,
'title' => $title,
'similarity' => $similarity
];
}
return ['context' => $context, 'sources' => $sources];
}
private function makeCompletionRequest($messages) {
$data = [
'model' => $this->model,
'messages' => $messages,
'temperature' => 0.1,
'max_tokens' => 500
];
$curl = curl_init();
curl_setopt_array($curl, [
CURLOPT_URL => 'https://api.openai.com/v1/chat/completions',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_POST => true,
CURLOPT_POSTFIELDS => json_encode($data),
CURLOPT_HTTPHEADER => [
'Authorization: Bearer ' . $this->apiKey,
'Content-Type: application/json'
],
CURLOPT_TIMEOUT => 30
]);
$response = curl_exec($curl);
$httpCode = curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($httpCode !== 200) {
throw new Exception("OpenAI API request failed with code: {$httpCode}");
}
$responseData = json_decode($response, true);
if (isset($responseData['choices'][0]['message']['content'])) {
return $responseData['choices'][0]['message']['content'];
}
throw new Exception('Failed to generate response: ' . json_encode($responseData));
}
}
?>Example Output: Here’s what happens during Step 5 (Context Assembly) and Step 6 (Response Generation):
Internal Context String Created:
$contextData = $this->assembleContext($searchResults);
// $contextData['context'] contains:
"Based on the following information:
Source {1} (ml_guide.txt): Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make decisions from data. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
Source {2} (ml_guide.txt): while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario.
Source {3} (rag_overview.txt): This approach helps reduce hallucinations and provides access to up-to-date information beyond the model's training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content.
"
// $contextData['sources'] contains:
[
[
'index' => 1,
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'similarity' => 0.847
],
[
'index' => 2,
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'similarity' => 0.723
],
[
'index' => 3,
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'similarity' => 0.234
]
]Messages Array Sent to OpenAI:
$messages = [
[
'role' => 'system',
'content' => 'You are a helpful assistant that answers questions based on the provided context. Use only the information from the context to answer questions. If the context doesn\'t contain enough information to answer the question, say so. Be specific and cite which sources you\'re using when possible.'
],
[
'role' => 'user',
'content' => 'Based on the following information:
Source {1} (ml_guide.txt): Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make decisions from data. There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
Source {2} (ml_guide.txt): while unsupervised learning finds patterns in unlabeled data. This approach enables computers to automatically improve their performance on a specific task through experience, without being explicitly programmed for every possible scenario.
Source {3} (rag_overview.txt): This approach helps reduce hallucinations and provides access to up-to-date information beyond the model\'s training data. The retrieval component typically uses semantic search through vector embeddings to find the most relevant content.
Question: What is machine learning?'
]
];Query Example 1: “What is machine learning?”
$result = $rag->query("What is machine learning?");
// Complete result array:
[
'question' => 'What is machine learning?',
'response' => 'Based on the provided information, machine learning is a subset of artificial intelligence that focuses on developing algorithms that can learn and make decisions from data. According to Source {1}, there are three main types of machine learning:
1. **Supervised learning** - uses labeled data to train models
2. **Unsupervised learning** - finds patterns in unlabeled data
3. **Reinforcement learning** - (mentioned but not detailed in the context)
As Source {2} explains, machine learning enables computers to automatically improve their performance on specific tasks through experience, without being explicitly programmed for every possible scenario. This learning approach allows systems to adapt and get better over time as they process more data.',
'sources' => [
[
'index' => 1,
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'similarity' => 0.847
],
[
'index' => 2,
'source' => 'ml_guide.txt',
'title' => 'Introduction to Machine Learning',
'similarity' => 0.723
],
[
'index' => 3,
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'similarity' => 0.234
]
],
'search_results' => [/* full search results array from Step 4 */],
'context_used' => true
]Query Example 2: “How does RAG reduce hallucinations?”
$result = $rag->query("How does RAG reduce hallucinations?");
// Complete result:
[
'question' => 'How does RAG reduce hallucinations?',
'response' => 'According to Source {3}, RAG (Retrieval-Augmented Generation) helps reduce hallucinations by providing access to up-to-date information beyond the model\'s training data. The system uses semantic search through vector embeddings to find the most relevant content from a knowledge base, which grounds the AI\'s responses in actual retrieved documents rather than relying solely on potentially outdated or incomplete training data. This retrieval-first approach ensures responses are based on factual, sourced information.',
'sources' => [
[
'index' => 1,
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'similarity' => 0.783
],
[
'index' => 2,
'source' => 'rag_overview.txt',
'title' => 'RAG Systems Explained',
'similarity' => 0.654
]
],
'search_results' => [/* full search results */],
'context_used' => true
]Query Example 3: “What is quantum computing?” (no relevant content)
$result = $rag->query("What is quantum computing?");
// Complete result:
[
'question' => 'What is quantum computing?',
'response' => 'I don\'t have information about that topic in my knowledge base.',
'sources' => [],
'search_results' => [],
'context_used' => false
]Notes:
- Context Assembly Intelligence:
- Automatically formats retrieved chunks into structured context
- Respects maximum context length limits
- Numbers sources for easy reference
- Preserves metadata for transparency
- Response Quality:
- Grounded answers: Responses cite specific sources
- Factual accuracy: Based only on retrieved content
- Source attribution: Clear references to which documents provided information
- Graceful degradation: Honest “I don’t know” when no relevant content found
- Complete Traceability:
- Question tracking: Original query preserved
- Source transparency: Similarity scores and document references
- Context visibility: Can see exactly what information was used
- Search results: Full details of what was retrieved
- Error Handling:
- No relevant content: Clear messaging when knowledge base lacks information
- API failures: Graceful handling of external service issues
- Empty knowledge base: Appropriate responses when no embeddings exist
The final output demonstrates how RAG transforms a simple question into a well-sourced, factual response with complete transparency about where the information came from!
Step 6: The Complete RAG System
Now we’ll create a main RAG class that orchestrates all the components and provides a simple interface for building and querying the knowledge base. A unified interface is important because:
- Simplifies usage for end users
- Manages component interactions
- Provides error handling and logging
- Enables easy configuration and customization
- Makes testing and debugging easier
<?php
require_once 'config.php';
class RAGSystem {
private $documentProcessor;
private $embeddingGenerator;
private $embeddingStore;
private $similaritySearcher;
private $responseGenerator;
public function __construct() {
$this->documentProcessor = new DocumentProcessor();
$this->embeddingGenerator = new EmbeddingGenerator(OPENAI_API_KEY);
$this->embeddingStore = new EmbeddingStore();
$this->similaritySearcher = new SimilaritySearcher(
$this->embeddingGenerator,
$this->embeddingStore
);
$this->responseGenerator = new RAGResponseGenerator(OPENAI_API_KEY);
}
public function buildKnowledgeBase($documents, $clearExisting = false) {
echo "Building knowledge base...\n";
if ($clearExisting) {
$this->embeddingStore->clearEmbeddings();
echo "Cleared existing embeddings.\n";
}
// 1
echo "Processing documents into chunks...\n";
$chunks = $this->documentProcessor->processDocuments($documents);
echo "Created " . count($chunks) . " chunks.\n";
// 2
echo "Generating embeddings...\n";
$embeddings = $this->embeddingGenerator->generateEmbeddings($chunks);
echo "Generated " . count($embeddings) . " embeddings.\n";
// 3
echo "Storing embeddings...\n";
$this->embeddingStore->addEmbeddings($embeddings);
}
public function query($question, $options = []) {
$topK = $options['top_k'] ?? 5;
$threshold = $options['threshold'] ?? 0.1;
echo "Searching for relevant information...\n";
// 1
$searchResults = $this->similaritySearcher->search($question, $topK, $threshold);
if (empty($searchResults)) {
echo "No relevant information found.\n";
return [
'question' => $question,
'response' => "I don't have information about that topic in my knowledge base.",
'sources' => [],
'search_results' => []
];
}
echo "Found " . count($searchResults) . " relevant chunks.\n";
// 2
echo "Generating response...\n";
$result = $this->responseGenerator->generateResponse($question, $searchResults);
return [
'question' => $question,
'response' => $result['response'],
'sources' => $result['sources'],
'search_results' => $searchResults,
'context_used' => $result['context_used']
];
}
?>Putting It All Together
Here’s how you would use the complete RAG system:
$rag = new RAGSystem();
$documents = [
[
'title' => 'file_1.txt',
'source' => 'docs/file_2.txt',
'content' => file_get_contents('docs/file_1.txt')
],
[
'title' => 'file_2.txt',
'source' => 'docs/file_2.txt',
'content' => file_get_contents('docs/file_2.txt')
]
];
$rag->buildKnowledgeBase($documents);
$result = $rag->query("How does RAG improve AI responses?");
echo $result['response'];Summary
Thoughts
I’m currently taking a Data Science course called “Applied Data Science Program: Leveraging AI for Effective Decision-Making“, and that drove a lot of the Python code and analysis of the embeddings vectors generated by the OpenAI API. I have a working example of the above at https://www.parhammofidi.com/ai-playground/rag/ where the above basis system was extended to handle URLs and PDF input and multiple files with relatively quick processing of decently sized files.
This was a pretty fun project to go through and obviously has many applications for people or companies that want to process large amounts of data without having to train their own models or just depend on an already trained model. The tutors, mentors, and teachers in my course remind us regularly that in 2025, there is a very likely chance that you won’t need to train a model to do what you want to do, you just have to know how to use the exist AI already out there.
Happy coding!