
Recently, I set myself a unique challenge: could I build a functional tool over a weekend whenever I had spare time, using only ChatGPT to write the code? Inspired by several similar experiments by my former boss Mark Ruddock and listening to a lot of what Rob Tyrie had to say about the AI space, I wanted to make something useful while testing the limits of ChatGPT as a coding partner. But there was one catch: I wasn’t going to write any code myself. Instead, I’d be the architect, giving directions through prompts and having ChatGPT do the coding. And since I had very limited time to do this, I knew this would be a high-speed iterative process. I did want give myself some time at the very end to polish up some code, but even then wanted to use ChatGPT to do a majority of the changes.
I wanted to build something I could use in my day to day. As many Japanese language learners will attest, much of that time is spent looking up words and grammar points, especially as I delve into more sophisticated reading and writing. I needed something that would give me the meanings of the dictionary words, too, along with grammar so it would be easier to deconstruct sentences and their contexts without jumping across different resources. Keeping that in mind, I started my project.
First, create a very simple interface through which users could paste Japanese text. My prompts were simple, beginning with basic HTML and then adding functionality. Here’s a snapshot of how, in these early stages, I initially guided ChatGPT:
- “Create a HTML page that will allow the user to paste in any text they want.”
- “When hovering over the text in the textbox, can distinct Japanese words/grammar/particles be identified?”
My goal was to have ChatGPT help me set up a way to highlight Japanese words, particles, and grammar points as users hovered over them. However, the initial setup didn’t quite work as expected.
- “Why doesn’t the highlighting work?”
With a bit of back and forth, ChatGPT identified some code issues, helping to adjust the HTML structure and JavaScript logic to make sure each word or particle could be individually highlighted.
- “Can you make it so that editable text will keep the formatting of the thing that is pasted?”
- “Editable text does not inherit the center justification; it should just do what is default.”
These and several other prompts really helped tune the user experience to make sure format consistency was natural for users pasting text in. Early on, I realized for parsing Japanese text I would need some specialized tools, and ChatGPT pointed me toward kuromoji.js, a JavaScript library for breaking down Japanese sentences into components.
- “What needs to be added to recognize words, grammar, and other parts of sentences?”
This prompt led ChatGPT to suggest using kuromoji.js to tokenize the text in Japanese, something that represented a very large milestone in terms of basic functionality.
Having completed the skeleton of the front-end, I started working on the back-end. To consider this resource complete, I wanted it to load data from three huge dictionaries: JMdict for general vocabulary, JMnedict for names, and KanjiDic2 for kanji information. All of their files were huge and contained loads of information in XML format that needed putting into some order within a MySQL database.
- “I want to download and load the full JMdict file into a MySQL database. What is a good schema to create?”
This prompt led ChatGPT to generate a solid database schema that organized dictionary entries by words, readings, meanings, and part-of-speech tags.
- “Can you create a PHP script that will read the contents of the file JMdict and load it into the schema you created above?”
- “The JMdict file I’m using is not just the English one; it’s the full one. What needs to change in the schema?”
With these prompts, I got a well-structured PHP script for importing the JMdict data into MySQL. ChatGPT also made adjustments to the schema, adding support for multiple languages within each entry.
- “Can you give me the fully changed SQL?”
Each modification led to a new version of the SQL script, which ChatGPT provided along with explanations for each alteration.
- “Can you send me the full PHP script to load in the multi-language JMdict file into the database?”
At this point, I had a complete import script for JMdict, but I also needed the database collation to handle Japanese characters properly.
- “What collation should the database have to handle all the character types?”
- “Can you put it all together so the database with the right collation is created and also the right tables are created in that database also with the right collation?”
With these prompts, ChatGPT guided me through setting up a UTF-8 collation, ensuring all Japanese characters (and other languages in JMdict) would display and query correctly.
- “How can I query this database to get the definition and all the details for a given character or characters?”
ChatGPT provided SQL queries to retrieve detailed entries based on any given input, allowing me to start testing the data retrieval functions.
- “Do you know about enamdict?”
- “Can you create a MySQL database for its structure?”
Finally, ChatGPT helped me set up the schemas and scripts for JMnedict and KanjiDic2, completing my backend database to support all three major Japanese dictionaries.
Japanese verbs and adjectives are richly conjugated, which complicates the dictionary lookups very much. I wanted to reduce the conjugated forms to dictionary (=base) forms so that the users can search words easily as they appear in the text. First, trying to avoid external dependencies, I asked ChatGPT to implement a conjugation function from scratch:.
- “I need a function that can convert Japanese verbs and adjectives to their dictionary form.”
Unfortunately, even iterative prompts didn’t help the model of ChatGPT to cover the full complexity of Japanese conjugation. An hour later, realizing the use of a library would be more efficient, I changed to MeCab, a morphological analyzer.
- “How to use MeCab with PHP to read a dictionary file?”
- “I got this error when installing the PHP module: E: Unable to locate package php-mecab.”
- “If I don’t want to do it this way, what are the alternatives?”
From these hints, I learned how to set up MeCab and avoid installation problems. Then, I made the configuration with the UniDic dictionary – a very powerful dictionary of the Japanese language, offering ample conjugation and grammar form information.
- “How to use the MeCab command-line tool to convert a binary dictionary to a CSV?”
- “Is there a CSV version of unidic-cwj readily available online?”
- “Without installing any external libraries, how can I access MeCab and pass it large amounts of data safely?”
- “How do I point MeCab to a particular dictionary folder?”
- “With MeCab and the different UniDic dictionaries, how does one use MeCab with all the dictionaries at the same time?”
- “How can I retain spaces and newlines when the text goes through to MeCab?”
With ChatGPT instructing, I properly set up MeCab to parse Japanese text-keeping spacing and formatting intact, so it would play nice with text being pasted into the tool.
With the database and conjugation handling complete, revisited the front end to give it some polish. I wanted to color-code parts of speech in order to make text parsing even more intuitive, and I asked ChatGPT to help do that:
- “Generate a pastel color palette that matches each part of speech and assign colors to the respective HTML elements.”
With the above, rather badly written prompt, ChatGPT provided a visually cohesive palette, making the UI more intuitive and user-friendly, and it updated all the CSS correctly. I also reduced JavaScript dependencies by moving some tasks to the backend, which improved the tool’s overall performance with a few more prompts.
A few extra feature implementations through AI included:
- Implementing a dictionary function and generating proper SQL to query for the information I wanted
- Adding visual tabs to the top of the page
- Creating a settings dialog along with credits
- Creating smart functionality to check for different iterations of a word
Finally, after a two day’s worth of prompts, tweaking, and iterating, I had a functioning prototype ready to go. You can check it out at https://www.parhammofidi.com/japanese.
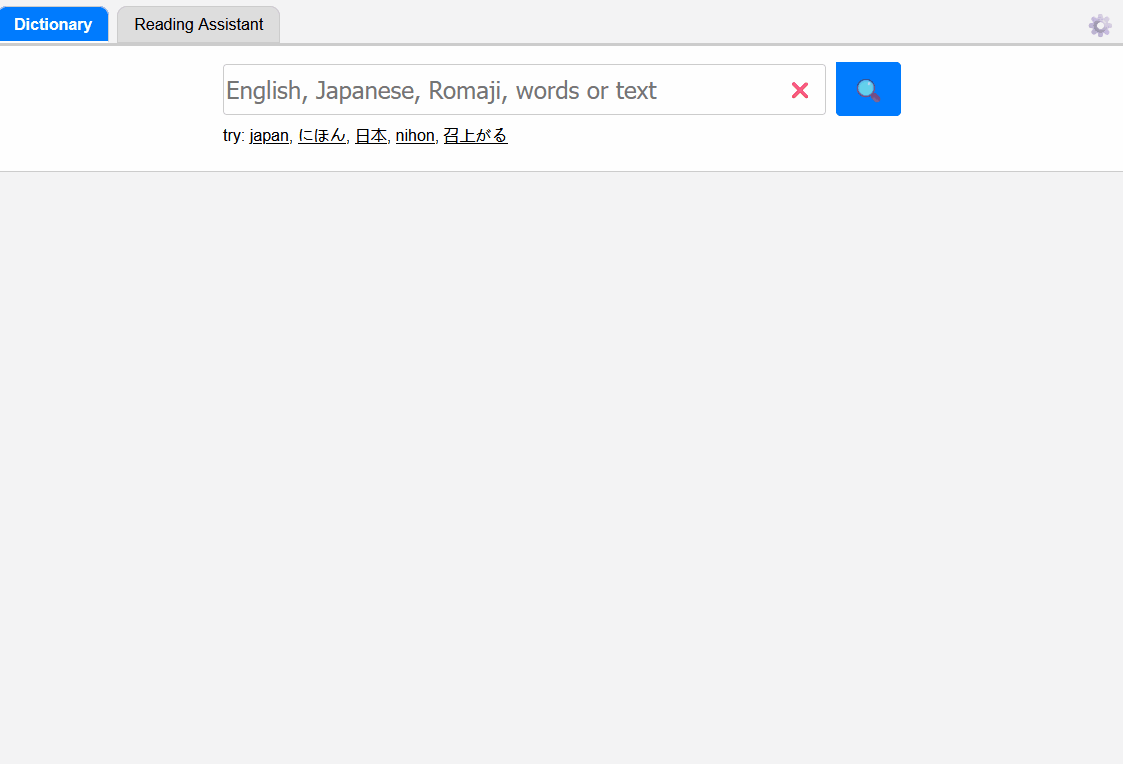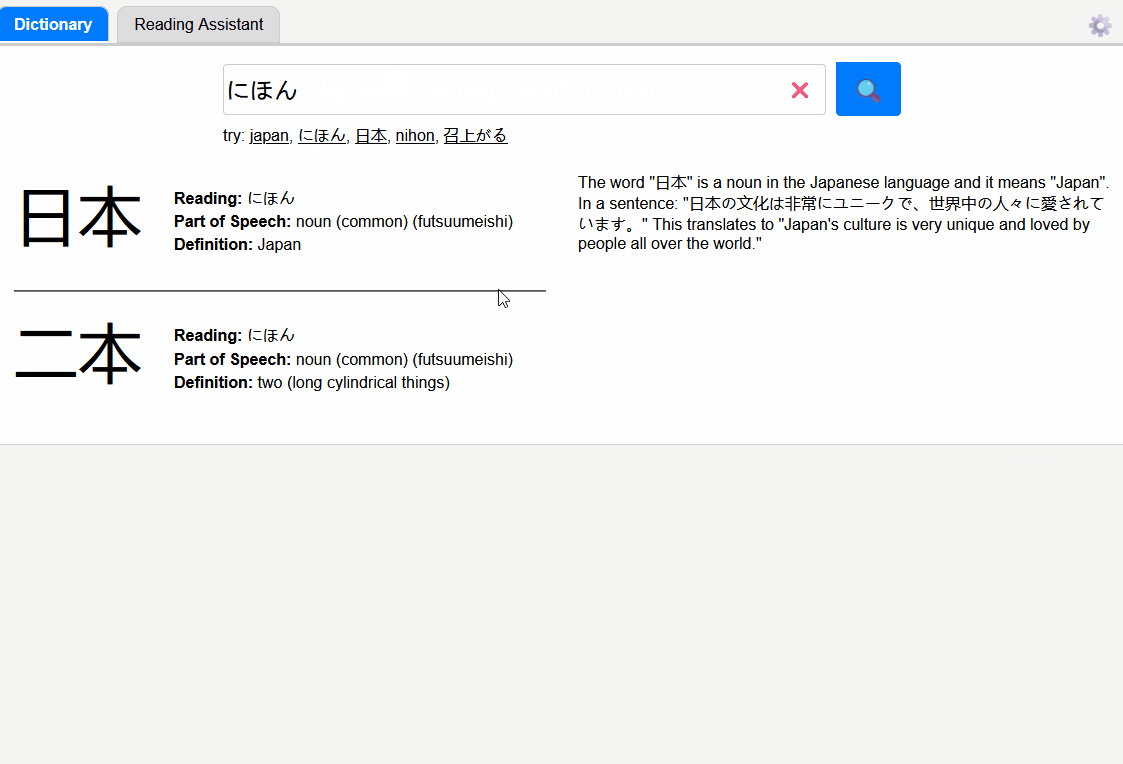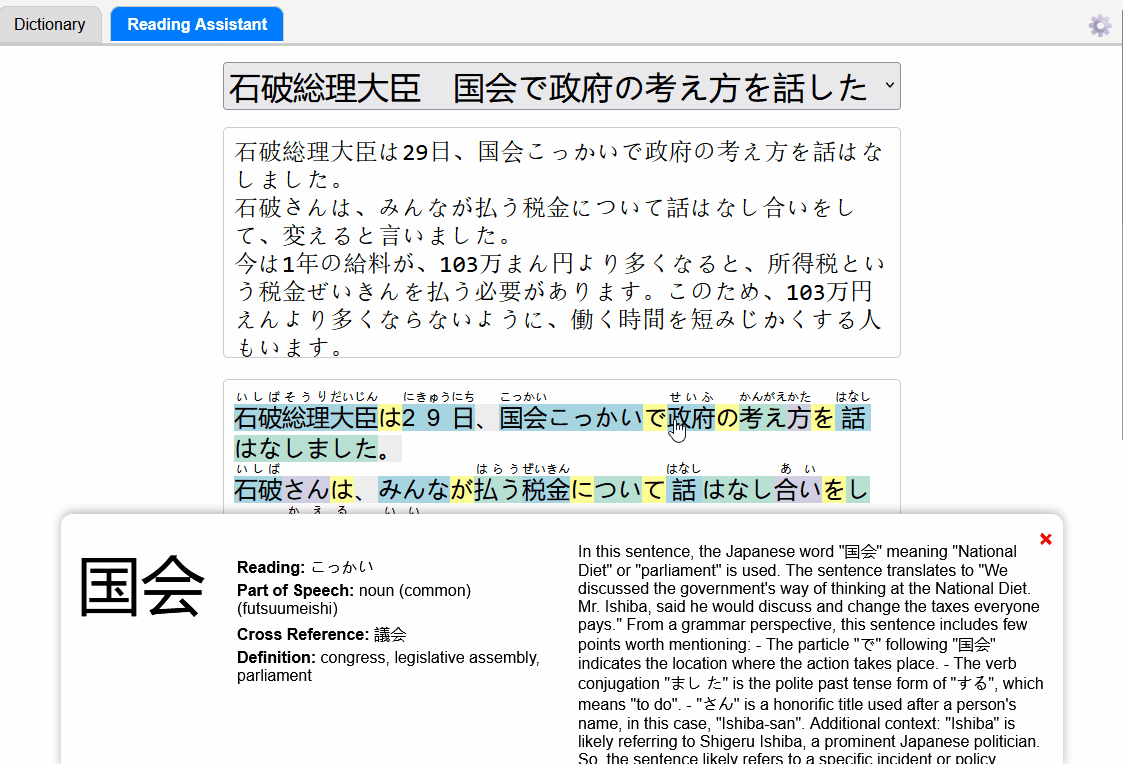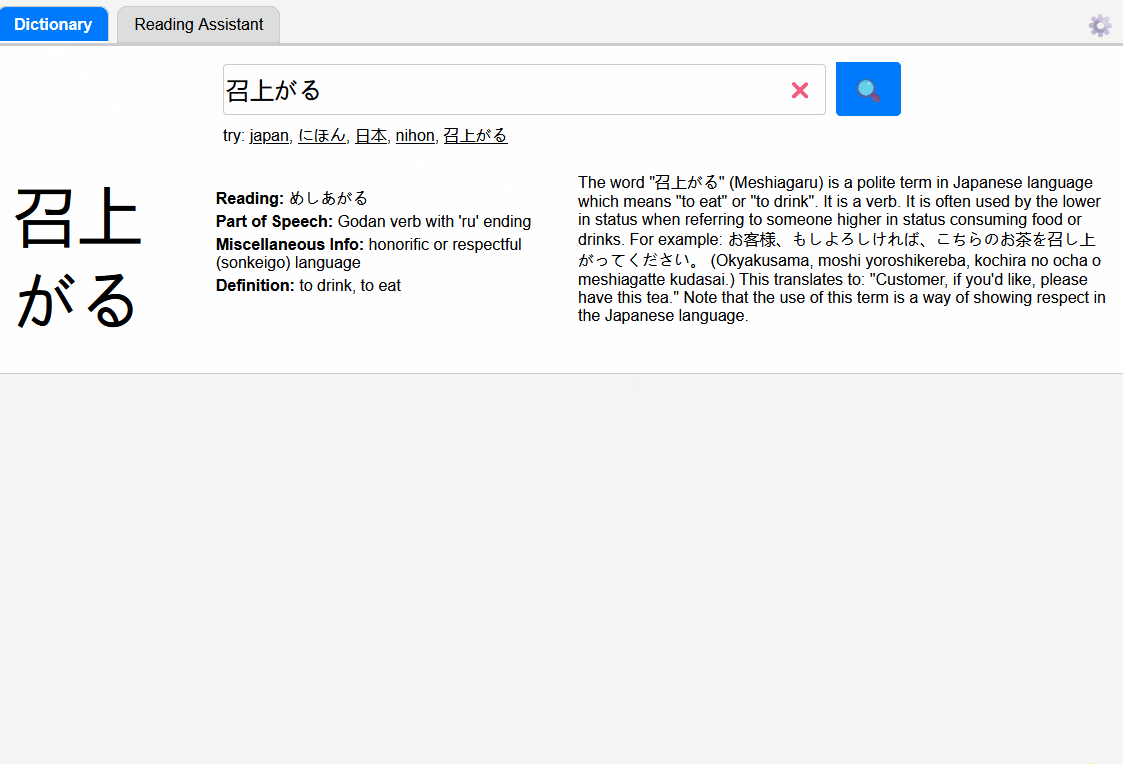
Here are my takeaways from this exercise:
- AI is prone to forgetting or changing previous solutions. I had to regularly prompt ChatGPT to “keep everything the same, but change X,” to preserve the structure I wanted while introducing new functionality. Back-peddling was a constant problem.
- It’s great for brainstorming options. Whenever I was unsure how to proceed, ChatGPT could outline different approaches, helping me pick the one that best suited the project’s goals.
- Broad problem statements yield good results. When I described general requirements, ChatGPT often returned helpful, adaptable solutions.
- AI excels at repetitive tasks. ChatGPT was particularly helpful for generating repetitive HTML, CSS, and database schemas, freeing me from tedious tasks.
- Database schema creation is fast and accurate. Given sample data, ChatGPT created highly accurate database schemas that saved me a lot of setup time.
It is an incredible collaboration workout, pushing both ChatGPT and me to new limits, having done the Japanese tool without manually coding. I really encourage people who want to see what’s possible with AI-driven coding to just experiment with stuff like this-you can do so much!